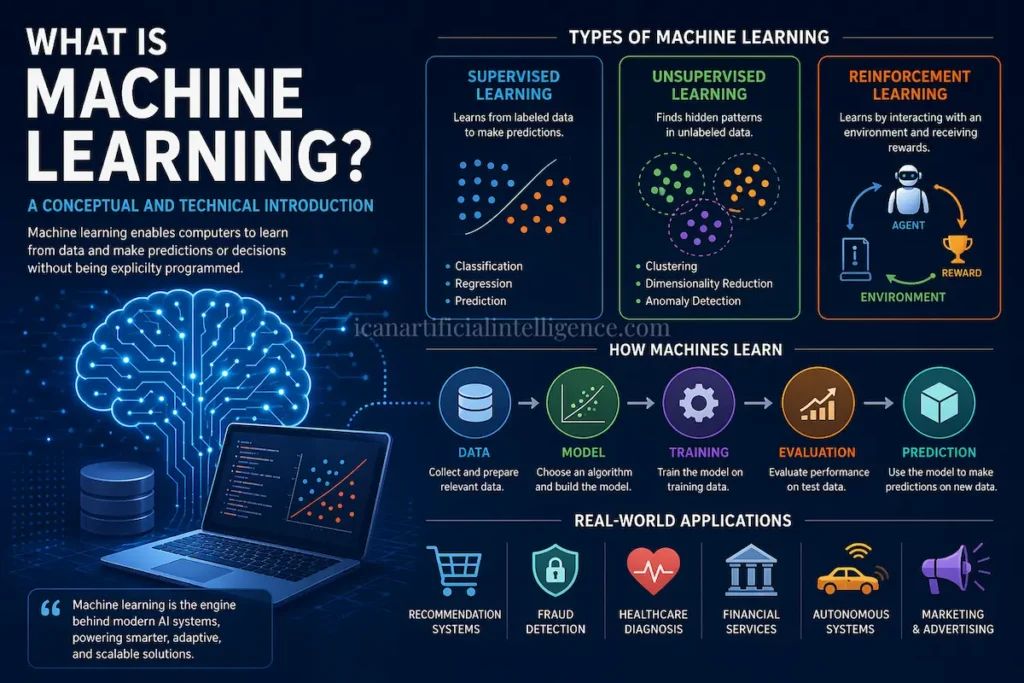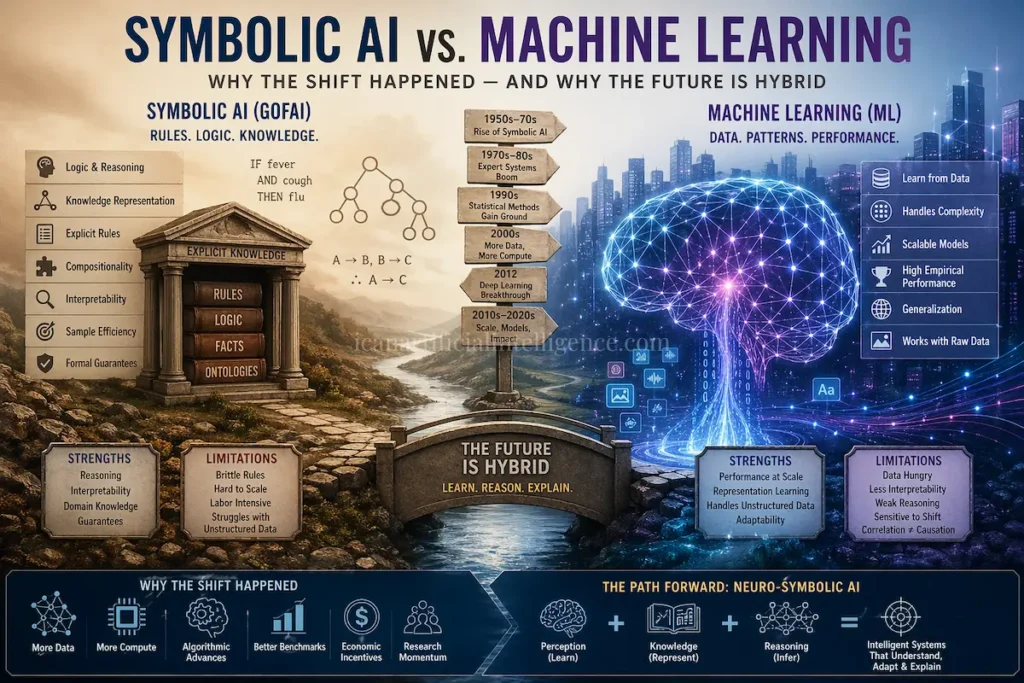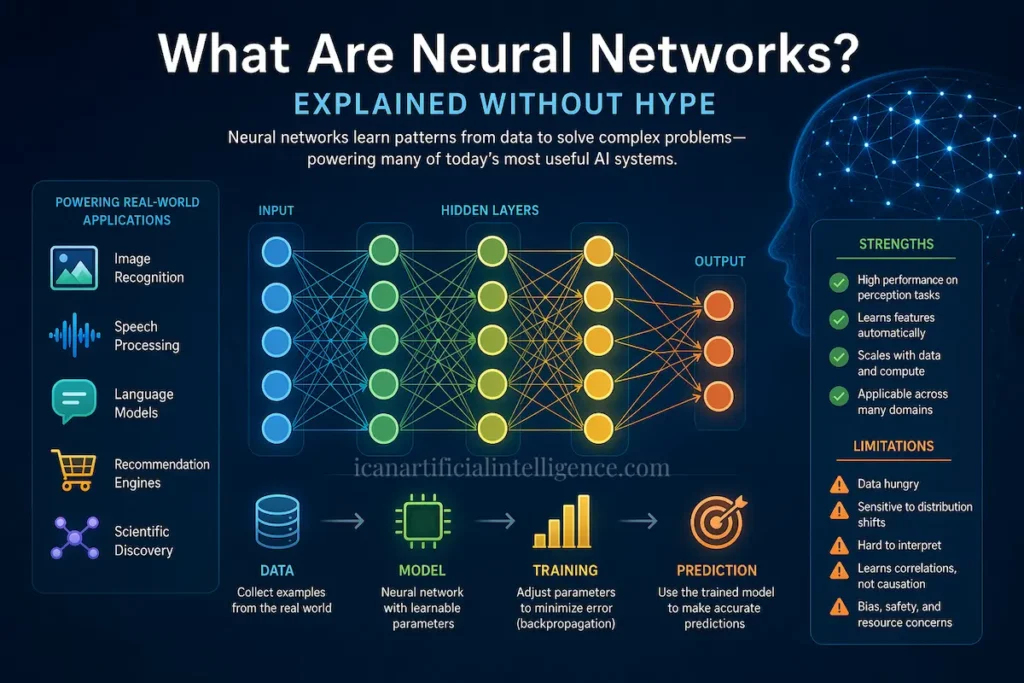
Neural networks are a family of machine‑learning models inspired loosely by biological brains. They transform inputs through layers of simple computational units, learn by adjusting internal parameters to minimize errors, and today power many widely used AI systems—image recognition, speech processing, language models, and recommendation engines. This article explains what neural networks are, how they work in practical terms, why they succeed in some domains and fail in others, common misconceptions, and where the field is heading. Claims are grounded in established research, with key references provided for verification and deeper study.
Plain‑Language Overview
At its core, a neural network is a programmable mathematical function made of many small components (“neurons”) connected in layers.
- Each neuron combines inputs using weights, applies a simple non‑linear function, and passes the result forward.
- A network learns by comparing its output to known correct answers and nudging its internal weights to reduce error.
- With enough data, compute, and an appropriate architecture, neural networks can learn complex patterns directly from raw data such as pixels, audio waves, or text tokens.
They are powerful engineering tools—but not magical systems that understand the world like humans do.
A Minimal Technical Picture
Artificial neuron
A neuron computes:
z = w · x + b
y = φ(z)
where x is the input vector, w the weights, b a bias term, and φ a non‑linear activation function (e.g., ReLU, sigmoid, tanh).
Network architecture
Neurons are arranged into layers. A feed‑forward network composes these layers into a function:
y = f(x; θ)
where θ denotes all learnable parameters.
Loss and training
- A loss function (e.g., cross‑entropy, mean squared error) measures how wrong predictions are.
- Backpropagation applies the chain rule to compute gradients of the loss with respect to parameters.
- An optimizer (SGD, Adam) updates parameters to reduce loss over many examples.
Generalization helpers
Techniques such as regularization, dropout, batch normalization, data augmentation, and early stopping help models avoid overfitting.
Common Neural Network Architectures
Multilayer Perceptrons (MLPs)
Fully connected layers; useful for tabular data and as building blocks in larger systems.
Convolutional Neural Networks (CNNs)
Designed for grid‑like data such as images. They exploit locality and translation invariance.
Recurrent Neural Networks (RNNs), LSTM, GRU
Historically important for sequential data (time series, early NLP). Many NLP tasks now favor Transformers, but RNNs remain relevant in constrained or streaming settings.
Transformers
Attention‑based models that scale well and handle long‑range dependencies. They underpin modern language models (e.g., BERT, GPT‑style systems).
Graph Neural Networks (GNNs)
Operate on relational or graph‑structured data such as molecules, networks, and knowledge graphs.
Hybrid and specialized models
Systems that combine neural components with symbolic modules, memory systems, or planners.
Why Neural Networks Work (Intuition, Not Hype)
- Function approximation
Deep networks can approximate very complex functions by composing simple non‑linear transformations. - Representation learning
Hidden layers learn increasingly abstract features (edges → textures → objects in vision; tokens → syntax → semantics in language). - Scale effects
Empirical evidence shows that more data, compute, and well‑designed architectures often yield better performance, within limits.
These properties explain practical success not human‑like reasoning or understanding.
What Neural Networks Need to Work Well
- Data: Quality and quantity matter. Self‑supervised learning and transfer learning reduce but do not eliminate data needs.
- Compute: Training modern models typically requires GPUs or specialized accelerators.
- Modeling choices: Architecture, loss functions, optimizers, and preprocessing strongly affect outcomes.
- Evaluation: Robust testing, including out‑of‑distribution checks, is essential.
Strengths
- Strong performance on perception tasks (vision, speech).
- Flexible: similar training pipelines apply across domains.
- Reduced need for manual feature engineering.
Limitations and Risks
- Data hunger: Performance often scales with data size.
- Generalization gaps: Models may fail under distribution shifts or adversarial perturbations.
- Interpretability: Internal representations are difficult to explain in human‑readable terms.
- Causality: Learning correlations does not imply causal understanding.
- Bias and fairness: Models can reproduce societal biases present in data.
- Resource costs: Large models consume significant energy and compute.
- Safety issues: Overconfidence, hallucinations, and misuse are real concerns.
Common Misconceptions (Debunked)
“Neural networks understand like humans.”
No. They learn statistical regularities and can mimic intelligent behavior without human‑style understanding.
“Bigger models are always better.”
Scaling helps in some regimes, but efficiency, robustness, and suitability to task matter.
“Neural networks replace all classical methods.”
In practice, symbolic reasoning, optimization, and rule‑based systems remain essential often in hybrid solutions.
Practical Evaluation Checklist
Before deploying a neural network system, ask:
- Are training, validation, and test sets truly independent?
- Has performance been evaluated under distribution shift?
- Are bias and fairness impacts measured?
- Is uncertainty calibrated where decisions have consequences?
- Is there monitoring and rollback after deployment?
Where Neural Networks Shine Today
- Image and video analysis (medical imaging, autonomous perception).
- Speech recognition and synthesis.
- Natural language processing (translation, summarization, chat systems).
- Recommendation systems.
- Scientific discovery (e.g., protein structure prediction systems that rely heavily on neural networks combined with domain constraints).
Future Directions (Concise)
- Self‑supervised and few‑shot learning to reduce labeling costs.
- More efficient models (compression, distillation, efficient attention).
- Neuro‑symbolic and causal approaches for better reasoning and robustness.
- Improved interpretability, uncertainty estimation, and alignment with human values.
Fact‑Check and Caveats
- Historical claims align with established literature: early neural models (1950s–60s), backpropagation revival (1986), deep learning resurgence (2006–2012), and transformer‑based models (post‑2017).
- Performance claims are empirical and task‑dependent; results must be validated on domain‑specific data.
- Neural networks are powerful statistical tools, not complete models of human cognition.
Conclusion
Neural networks are neither magical minds nor passing trends. They are powerful statistical tools that have earned their place by delivering strong empirical results on problems where traditional rule-based systems struggle especially in perception, language, and large-scale pattern recognition. Their success comes not from human-like understanding, but from the ability to learn complex functions from data using well-understood mathematical principles.
At the same time, their limitations are real and important. Neural networks depend heavily on data and compute, often lack transparency, and struggle with reasoning, causality, and robust generalization outside their training distribution. Treating them as general intelligence systems or as replacements for all other forms of computation leads to confusion and misplaced expectations.
The most productive way forward is not blind enthusiasm or outright skepticism, but careful, context-aware use. Neural networks work best when applied to problems that match their strengths, evaluated rigorously, and combined with other approaches where appropriate. As research continues toward more efficient, interpretable, and hybrid systems, neural networks should be understood for what they are: highly capable learning machines, not substitutes for human judgment or reasoning.
Used responsibly, they remain one of the most important engineering tools of modern computing and understanding their true nature is the first step toward using them well.
Selected References
- LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature.
- Rumelhart, D. E., Hinton, G. E., & Williams, R. J. (1986). Learning representations by back‑propagating errors. Nature.
- Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). ImageNet Classification with Deep Convolutional Neural Networks.
- Vaswani, A., et al. (2017). Attention Is All You Need.
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning.
- Kaplan, J., et al. (2020). Scaling Laws for Neural Language Models.
- Marcus, G. (2018). Deep Learning: A Critical Appraisal.
- Sutton, R. S., & Barto, A. G. (2018). Reinforcement Learning: An Introduction.
This article is intended as a clear, non‑sensational introduction for readers seeking a grounded understanding of neural networks and their real capabilities.